Introduction
À la suite du cours de VHDL que j'ai suivi dans le cadre de ma formation d'ingénieur, j'ai souhaité aller un plus loin dans la découverte et l'utilisation de cette logique de développement hardware dont j'expliquerais les principes dans la suite de cet article. Pour me définir un défi intéressant, j'ai choisi de concevoir l'architecture puis de décrire le comportement en VHDL de mon propre microprocesseur, en partant de zéro.
S'il s'agissait déjà d'un objectif ambitieux, pour rendre le projet encore plus intéressant, je me suis imposé la contrainte supplémentaire de ne pas utiliser de documents ou de support internet pour la conception de ce microprocesseur afin de l'aborder avec une démarche "naïve" (uniquement influencée par mes souvenirs d'un cours de microcontrôleur). L'intérêt de cette façon de procéder est double : j'ai, à l'issue du projet et grâce au erreurs successives, une bien meilleure compréhension du langage VHDL et de ses mécanismes mais surtout de la manière d'envisager la conception d'un système complexe en électronique numérique (et de manière plus globale).
Cet article retrace donc toute la création, de la définition de l'architecture à l'implémentation physique et aux tests fonctionnels de mon processeur simpliste. Le projet VHDL (au format Xilinx ISE Webpack) est bien évidemment disponible en fin d'article.
Avant-propos sur le VHDL
Le VHDL (VHSIC Hardware Description Language), standard IEEE, est un langage de description hardware qui permet de décrire des architectures et comportements, c'est à dire de choisir le branchement de portes logiques. Le code n'est donc, contrairement à un langage de programmation comme le C, pas exécuté séquentiellement par un processeur.
Par exemple, la ligne VHDL a <= b and c; implémentera physiquement une porte ET prenant en entrée les fils/signaux b et c et ayant pour sortie le fil/signal a. C'est donc radicalement différent de l'instruction C a = b & c; qui demande au processeur de faire le calcul b ET c, puis de le mettre dans la variable a.
Le VHDL (qui n'est par ailleurs pas le seul langage de description hardware) appartient donc à l'électronique numérique en non à l'informatique.
Définition de l'architecture
Avant de décrire le processeur en VHDL, il faut passer par une phase de définition de l'architecture qui sera mise en place. Cette étape essentielle était un processus itératif durant lequel, en faisant des représentations schématiques successives de l'ensemble, les erreurs et limitations de l'architecture ont été pour la plupart identifiées et corrigées.
Le modèle final de mon système est le suivant :
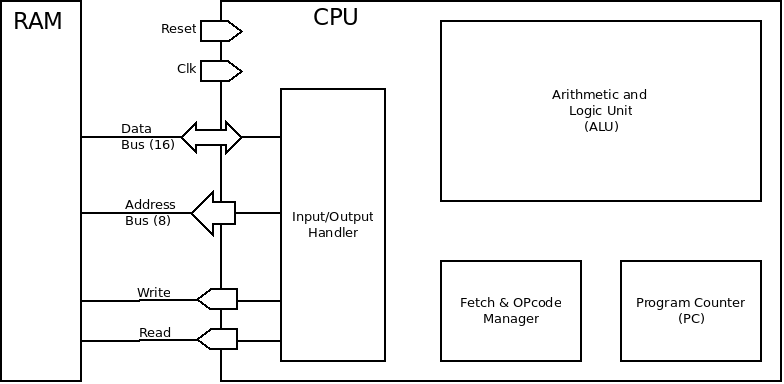
Définissons chaque élément du CPU :
- Le Fetch & OpCode Manager est chargé de récupérer les instructions dans la mémoire et de les passer à l'ALU et au reste du système ;
- Le Progam Counter (PC) détient l'information de l'adresse de la prochaine instruction à charger par le Fetch & OpCode Manager. Il s'incrémente normalement après chaque instruction, mais peut être directement changé lors d'un saut (GoTo).
- L'ALU (Arithmetic and Logical Unit - Unité Arithmétique et Logique) est le cœur CPU : elle peut effectuer des opérations logiques (ET, OU, etc.) et arithmétiques (+, -, etc.) sur ses registres.
- Le bloc entrées/sorties est contrôlé par le Fetch & OpCode Manager. Il s'occupe de l'état des entrées/sorties, par exemple : connecter la sortie de l'ALU au bus de données, mettre le contenu du PC dans le bus d'adresse, etc.
Deux cycles s'exécutent en alternance :
- Le processeur récupère l'instruction située à l'adresse PC. C'est le fetch.
- Il exécute cette instruction. Cela peut être une opération arithmétique/logique, une demande/envoi de donnée vers la RAM, ou encore une commande de contrôle.
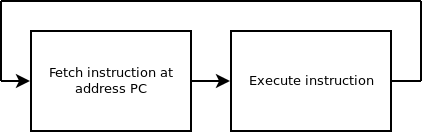
En concevant l'architecture de mon CPU, j'ai dû déterminer un jeu d'instruction et une structure pour ces dernières dans la mémoire. Le jeu d'instruction est l'ensemble des commandes qu'est capable d'exécuter le CPU. Une instruction sera structurée de la manière suivante :
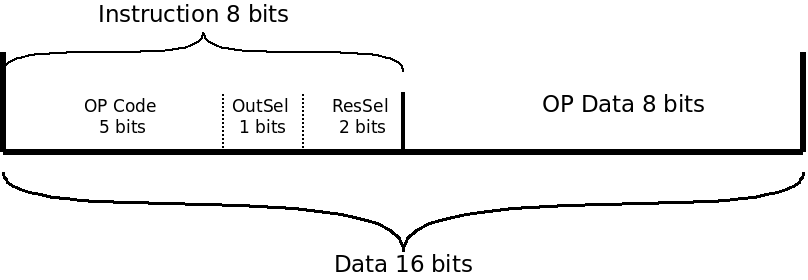
La longueur est fixée à 16 bits et le temps d'exécution à une période d'horloge (donc deux, si l'on compte le fetch).Le champ OP Data contient les arguments de l'instruction. Les champs OutSel et ResSel seront détaillés dans la partie sur l'ALU. Pour l'heure, concentrons nous sur l'OP code :
| Nom | OPCode | Description |
|---|---|---|
| NOP | 00000 | Ne fait rien (No OPeration) |
| Get.X @ | 00001 | Récuperer le contenu du registre X vers l'adresse @ de la mémoire |
| Set.X @ | 00010 | Met le contenu de l'adresse @ dans le registre X (inverse de Get) |
| SetL.X Y | 00011 | Met la valeur Y (sur 8 bits) dans le registre X. Contrairement à l'instruction précédente, la valeur est fixée dans l'instruction : il s'agit d'une constante |
| Goto @ | 00110 | Met l'adresse @ dans le PC, c'est à dire indique que la prochaine instruction sera fetchée à l'adresse @ et non PC+1 |
| GotoIfNull.X @ | 0010X | Met l'adresse @ dans le PC si et seulement si le registre X vaut 0. Autrement dit, c'est un saut conditionnel |
| Inc.X | 0100X | Incrémente le registre X |
| Dec.X | 0101X | Décrémente le registre X |
| Add | 00111 | Additionne les registres en eux |
| Sub | 01100 | Soustrait les registre entre eux |
| And | 01101 | Fait un ET logique entre les registres |
| Or | 01110 | Fait un OU logique entre les registres |
J'ai choisi ces instructions pour avoir un éventail de fonctionnalités suffisamment grand pour mettre en place sans restriction tout type d'algorithmes, tout en essayant de ne pas compliquer outre mesure le système.
L'ALU
L'ALU est la partie du CPU qui fait les calculs à proprement parlé. Elle contient deux registres dans lesquels on peut mettre une valeur, faire les calculs et récupérer le contenu. Il s'agit donc du bloc autour duquel s'articule le processeur.
Architecture
Voici l'architecture telle que je l'ai conçue :
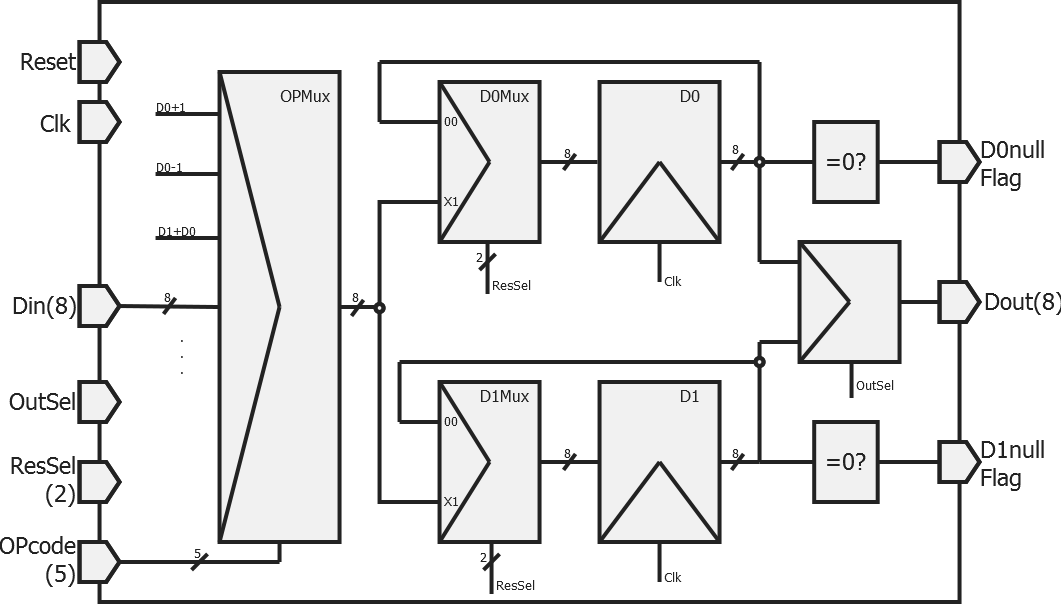
Tous les registres sont supposés connectés au reset asynchrone, et actifs sur un front montant d'horloge.
Elle fonctionne sur le principe suivant :
- L'OPMux est le multiplexeur permettant de choisir l'opération. En entrée, on retrouve toutes les opérations possibles, tandis qu'une seule est choisie en sortie, en fonction du code de l'opération ;
- Les deux registres D0 et D1 contiennent les variables utilisées par le processeur, qui sont les opérande de l'ALU ;
- Les deux multiplex D0Mux et D1Mux permettent de choisir si l'on souhaite copier le résultat de l'opération dans le registre ou conserver leur valeur précédente ;
- Les "flags" sont des sorties booléennes (Vrai ou Faux) qui permettent de vérifier une condition (ici, D0/D1=0?). Cela permet d'effectuer des sauts conditionnels comme "Aller à l'adresse @1 si D0=0".
- Enfin, un dernier multiplexeur permet de choisir à quel registre est connectée la sortie.
Pour ajouter des instructions, il suffirait d'ajouter des entrées au multiplexeur OPMux. Le code de l'instruction (OPCode) étant, d'après mes spécifications, sur 5 bits, on a un total de 2^5=32 codes possible.
Remarque : La sortie de l'ALU n'est utilisée que par la commande "Get". Le bit OutSel ne sert donc que dans ce cas. On peut aisément l'utiliser pour coder l'OPCode d'autres opération. On a donc, en pratique 2^6-1=63 codes possibles (le "-1" provient du fait que l'on a tout de même deux Get : Get D0 et Get D1). L'architecture étant définie de façon à garder un schéma le plus simple et le plus compréhensible possible, je laisse consciemment ces optimisations de coté.
Code VHDL
Pour ne pas alourdir cet article déjà relativement complexe, je ne vais pas détailler l'intégralité de mon code VHDL. Je vais tout de même relever les blocs intéressants.
Les multiplexeurs sont décrit de la manière suivante :
mux <= entree0 when Sel=sel0 else entree1 when Sel=sel1 else .... ;C'est à dire connecter le fil "mux" à l'une des entrées, en fonction du sélecteur "Sel". Par exemple, pour OPMux, ses entrées sont des opérations arithmétiques ou logique. Il faut bien noter qu'il s'agit d'un bloc combinatoire qui, à cause des temps de propagation, met un certain temps à se stabiliser. Par exemple, si le signal de sélection change subitement et passe par 10 portes ET ayant un délai de propagation de 1ns, la sortie du multiplexeur sera inconnue pendant 10ns.
Un registre avec son multiplexeur se décrit de la manière suivante :
D0Mux <= OPMux when Sel='1' else D0; --mux
D0 <= ( others => '0' ) when reset='1' else D0Mux when rising_edge(clk); --registreLe registre copie son entrée (D0Mux) à chaque front montant d'horloge et le conserve jusqu'au prochain front montant. Le multiplexeur d'entrée offre deux sorties possible : soit une recopie de la sortie du registre (c'est à dire ne rien changer), soit une copie d'un autre signal.
On ne synchronise les registres que sur des fronts d'horloge. Les signaux combinatoires ont donc exactement une période d'horloge pour être stable. Cela implique que la fréquence maximale dépend du temps de stabilisation le plus long dans la partie combinatoire comprise entre deux registres synchrones. Nous étudierons cette caractéristique à l'échelle du processeur en conclusion de ce projet.
Test et validation
La deuxième partie critique (après la définition des architectures) est le test des blocs fonctionnels. La suite Xilinx ISE Webpack que j'utilise propose un simulateur, ISim, qui permet de relier virtuellement les portes logiques du design et d'observer les signaux. La simulation est une partie fondamentale du VHDL ; certaines commande ne fonctionnant qu'en simulation sont d'ailleurs définies.
Pour tester l'ALU, j'ai injecté dans les entrées des signaux pour analyser le résultat. Par exemple :
OpCode <= OPCodeINC0; --Incrémenter D0
ResSel <= "01"; --Mettre le résultat dans D0
OutSel <= '0'; --Mettre en sortie D0La sortie est la suivante, en définissant également une clock et un reset initial :
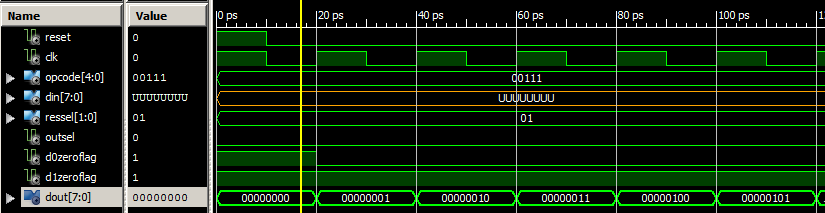
On observe bien en sortie, sur DOut, l'incrémentation du registre sur chaque front montant de clk. J'ai réalisé d'autres simulations plus ou moins complexes qui m'ont finalement permis de valider le bon fonctionnement de l'ALU.
L'étape suivante est l'ajout des circuits de contrôle autour de l'ALU pour finalement obtenir un CPU fonctionnel.
Le CPU
Architecture
Définir l'architecture du CPU correspond à décider de l'implémentation de chacun des petits blocs de contrôle que nous avons précédemment définis. Le schéma complet, qui reste étonnement simple, est le suivant :
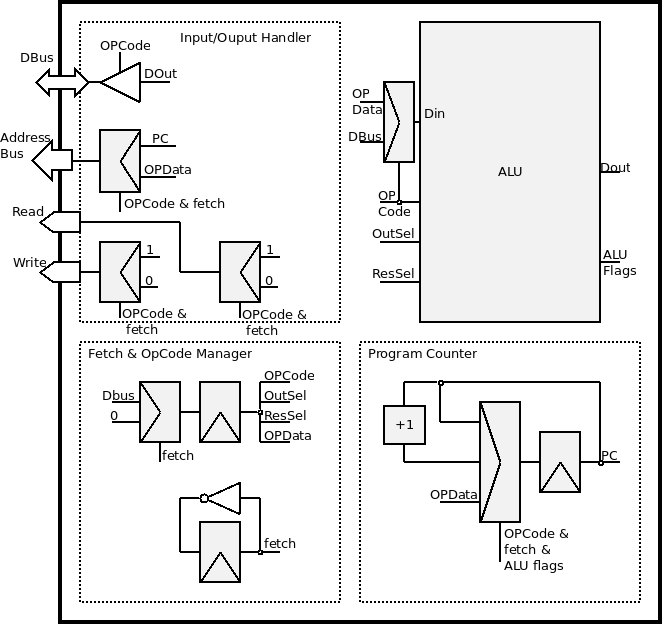 Les entrées reset et clk ne sont pas représentées. Les "&" en entrées des multiplexeurs indiquent que la sortie est sélectionnée par tous les signaux mentionnés.
Les entrées reset et clk ne sont pas représentées. Les "&" en entrées des multiplexeurs indiquent que la sortie est sélectionnée par tous les signaux mentionnés.
Nous alons, une nouvelle fois, prendre les blocs individuellement afin d'exprimer assez simplement leur fonctionnement :
- Le Fetch & OpCode Manager s'occupe de gérer l'alternance entre le cycle fetch et instruction, et conserve l’instruction à exécuter pendant tout le cycle d’instruction, après chaque fetch. Par ailleurs, il décompose cette instruction en ses composantes atomiques, utilisées par le reste du CPU (et notamment l'ALU). Il est très important de noter qu'il prend la valeur zéro pendant les fetch. Cela correspond à un NOP, car il ne faut pas que le reste du système effectue des opérations pendant un cycle de fetch !
- Le Program Counter n'a qu'une sortie : la valeur suivante d'adresse à fetcher. Il peut changer à chaque front montant d'horloge pour trois valeurs possibles :
- PC + 1, toujours après un fetch ;
- PC, c'est a dire lui même. Toujours en fin de cycle d'instruction, sauf dans le cas suivant ;
- OP Data, lors d'un saut conditionnel ou inconditionnel, on va à l'adresse passée en argument en vérifiant, si nécessaire, les flags de l'ALU.
- L'ALU a déjà été détaillée dans la partie précédente. On notera le petit multiplexeur à son entrée Din, qui distingue les deux seules instructions de mon jeu qui l'utilise : Set et SetL. Dans le cas SetL, on met directement l'OP Data, tandis que dans le cas Set, on cherche la valeur dans la RAM et on connecte donc le databus à Din.
- Le gestionnaire d'entrées/sorties s'adapte simplement au reste pour choisir l'état des ports. Par exemple, si l'OPCode est un Get, il va mettre Read à 0, Write à 1, l'adresse à l'OP Data (l'argument de l'instruction) et connecter le bus de données à Dout de l'ALU.
Code VHDL
Ce bloc utilise les même principes précédemment définis. J'aimerais toutefois mettre en avant le code du buffer qui décide de l'état de DBus.
Si l'on utilisait le code suivant :
dataBus <= Dout when OPCode=OPCodeGET else (others => '0');Si l'OP Code était un GET, on connecterait effectivement le bus à la sortie Dout de l'ALU, mais dans toute autre situation (un fetch, par exemple), si un périphérique tentais d'utiliser le bus, le moindre '1' (+VCC) se connecterait directement au '0' (GND) que l'on force : c'est un court circuit!
Pour éviter cela, on utilise le troisième état, 'Z', qui signifie très haute impédance, autrement dit ne rien connecter du tout. Le second utilisateur peut donc mettre indifféremment des '0'/'1' sans craindre de problème. Le code de ce buffer trois état est donc :
dataBus <= Dout when OPCode=OPCodeGET else (others => 'Z');Test et validation
Le test du CPU est autrement plus compliqué que celui de l'ALU. Les comportements sont en effet moins évidents à déterminer et on a une plus grande variété de problèmes potentiel à détecter. J'ai donc, dans un premier temps, fait des tests unitaires en injectant une à une dans le CPU avant de tester des algorithmes avec des saut conditionnels et des calculs imbriqués.
Par exemple, la capture suivante correspond à de simple SETL sur les registre D0 puis D1 :
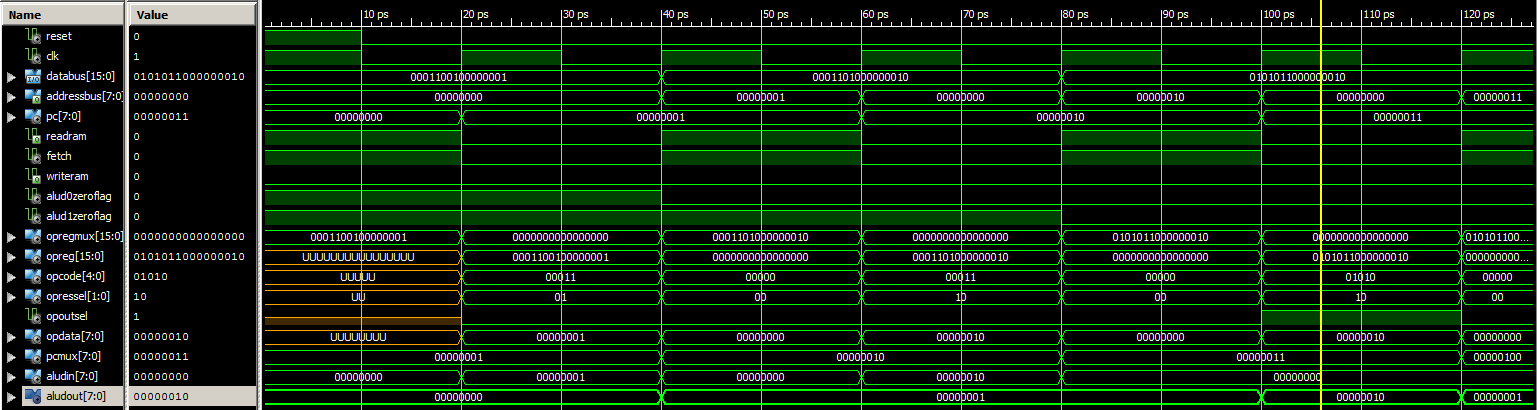
Nous n'analyserons pas dans cet article ces formes d'ondes (et vous m'en remercierez !), mais on remarque tout de même aisément l'alternance entre le cycle Fetch et le cycle Instruction avec le signal fetch. De même, on observe l'incrémentation du PC après chaque Fetch.
L'examen approfondi de différentes simulations m'a permis de valider le bon fonctionnement de mon CPU.
Du microprocesseur à l'ordinateur
L'ajout de la RAM
Pour "utiliser" ce processeur en dehors de la simulation ISim, il faut évidemment ajouter la mémoire contenant les données et les instructions. Pour cela, j'ai réalisé le module suivant en VHDL qui contrôle une mémoire (une liste de registres). Il est cohérent avec l'architecture précédemment définie : 16 bits de données, 8 bits d'adressage, un Read et un Write. Voici une représentation schématique de ce module :
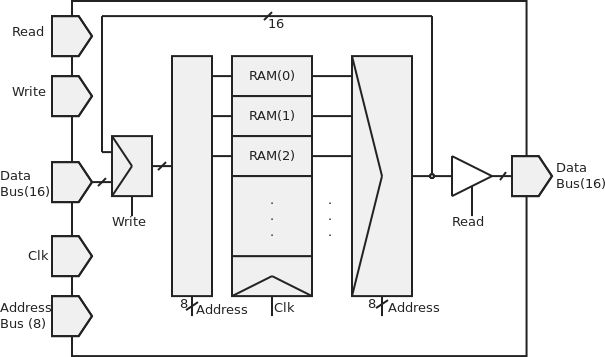
Le port "DataBus" est représenté deux fois car il s'agit d'un bus bidirectionnel, tantôt utilisé comme entrée, tantôt comme sortie.
L'idée est simple (pour preuve, le code VHDL fait 3 lignes!) :
- Si Read=1, on met le contenu du registre dont l'adresse donnée par le bus d'adresse dans le bus de données. Si Read=0, alors on met la sortie à l'état Z (haute impédance).
- Si Write=1, on met le contenu du bus de données dans le registre dont l'adresse donnée par le bus d'adresse. Si Write=0, alors on met dans ce registre sa propre valeur à la place.
Par sécurité, dans la description VHDL, j'ai fait en sorte que ces deux notions soient exclusives : la situation Read=Write=1 est strictement identique à la situation Read=Write=0.
Voici le code VHDL, légèrement simplifié, correspondant (RAMbuffer représentant le multiplexeur de gauche sur le diagramme) :
dataBus <= RAM(addressBus) when ReadRAM='1' else ( others => 'Z' );
RAMbuffer <= dataBus when WriteRAM='1' else RAM(addressBus);
RAM(addressBus) <= RAMbuffer when rising_edge(clk);La programmation de la machine
Pour utiliser "l'ordinateur" ainsi créé, il suffit de mettre dans la RAM un programme (en langage machine) et ses données.
Par exemple programme ci-dessous :
- Initialise un nombre à 10 ;
- L'incrémente tant qu'il est différent de 20 ;
- Le décrémente tant qu'il est différent de 0, puis retourne à l'étape précédente.
0001100100001010 0001101000010100 0110001000000000 0010100000000110 0100000100000000 0011000000000001 0010000000000001 0101000100000000 0011000000000110Comme c'est absolument illisible, dans ma lancée, j'ai codé un assembleur pour mon jeu d'instruction. Il s'agit d'un script AWK qui prend en entrée un fichier assembleur au format donné dans les spécification de mon jeu d'instruction et donne en sortie le binaire en langage machine. Par exemple, pour le même programme que ci-dessus, en voici le code assembleur :
SetL.0 10 ;Init Reg0 to 10
increment:
SetL.1 20 ;Put 0 in Reg1
Sub.1 ;Reg1=Reg1-Reg0
GotoIfNull.1 decrement ;if Reg1=0...
Inc.0 ;else, increment Reg0
Goto increment ;restart (until Reg0=20)
decrement:
GotoIfNull.0 increment ;if Reg0=0...
Dec.0 ;else, decrement Reg0
Goto decrement ;restart (until Reg0=0)C'est plus facile ainsi ! Je ne vais pas m’attarder sur cet assembleur qui pourrait avoir son article à lui seul, et passer à la dernière partie de ce projet : l'implémentation physique du processeur !
Implémentation physique sur FPGA
Pour donner une dimension pratique à ce projet, j'ai décidé de le porter sur un circuit intégré FPGA (field-programmable gate array), un réseau logique configurable dont les portes logiques internes peuvent être "branchées" en fonction de la description VHDL. J'utilise une Digilent Basys2 qui intère un Xilinx Spartan-3E (100 000 portes logiques), prêtée par l'association de robotique ECEBorg.
Si je ne faisait que configurer la puce avec mon CPU et sa RAM, l'ensemble fonctionnerait, mais on ne verrait rien dans la mesure ou il n'y a pas de sortie "visible" au processeur. Pour observer le fonctionnement, j'ai créé un programme très simple qui incrémente une case de la RAM, et j'ai ajouté un petit "hack" à ma RAM pour connecter cette case en sortie du bloc, pour la relier à des LED. L'horloge est branchée sur une horloge 60Hz, et le reset asynchrone sur un switch. La vidéo suivante montre le fonctionnement de l'ensemble :
Voici le code du programme utilisé :
SetL.0 0 ;init reg0 to 0
loop:
Inc.0 ;increment reg0
Get.0 4 ;RAM(4)=reg0
Goto loop ;infinite loop
0 ;RAM(4), hard wired to the LEDsConclusion
Les performances de mon CPU
Bien que les performances du processeur n'aient jamais été un objectif de ce projet, il est tout de même intéressant d'analyser le système résultant :
- Toutes les instructions s’exécutent sur un temps constant de deux cycles d'horloge et sont sur 16 bits.
- Le temps de propagation maximal (worst case) pour l'implémentation sur Spartan-3E est 7 ns. Cela correspond à une fréquence d'horloge maximale de 150MHz soit 75.000.000 instructions par seconde. Dans l'absolu, cette fréquence ne veut pas dire grand chose car elle est fortement déterminée par le FPGA. Il y a fort à parier qu'elle peut varier du simple au double en fonction des modèles.
- Il y a besoin d'un nombre réduit de portes logiques pour implémenter le processeur. La capture suivante montre l'utilisation des éléments logique pour le Spartan-3E100.
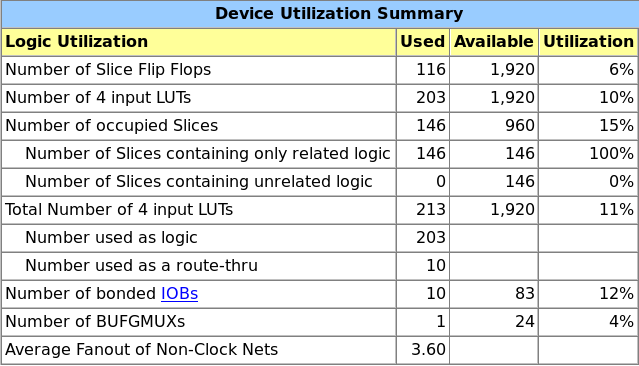
- Tel qu'il est construit, beaucoup des 256 instructions sont consommées par les champs OutSel et ResSel. Au final, sur 8 bits, il ne reste que 32 instructions utilisables. J'ai consciemment fait ce choix pour simplifier les sélecteurs des multiplexeurs, mais il s'agit d'un gachit important de mémoire. De plus, il ne serait pas aisé d'ajouter des registres à l'ALU avec cette approche.
- Pire! 50% de la mémoire des données est inutilisable car l'ALU est 8 bits alors que le bus est 16 bits...
Pour aller plus loin
Au cours du développement et de la rédaction de cet article, j'ai eu un certain nombre d'idées pour améliorer considérablement mon processeur :
- Corriger le problème des 50% de mémoire de données inutilisable. La meilleure approche serait d'avoir une mémoire de 8 bits de large, et de fetcher 2 cases consécutive à chaque fois. L'apporche simple serait d'avoir deux mémoires séparées : une pour les instruction de 16 bits de large, et une pour les données de 8 bits de large (en conservant un bus 16 bits).
- La forme des instructions, avec le champ ResSel et OutSel est un dispendieuse et assez inconfortable à utiliser. Elle permet de faire des choses "bizarres", comme incrémenter une variable sans conserver le résultat ou encore mettre une variable à zéro tout en faisant un goto. Il faudrait reprendre le rôle du Fetch & OpCode Manager pour qu'il génère plus intelligemment ces champs en fonction de l'OP Data.
- Ajouter des fonctionnalités ! Gestion des interruptions, ajout d'une stack, ajout d'instructions, de GPIO etc.
- Pourquoi pas profiter des instructions n'utilisant pas le bus pour fetcher dans le même temps que l'instruction s’exécute !
Téléchargement
Cliquez sur le lien suivant pour télécharger les sources du projet (projet VHDL et assembleur AWK) : https://github.com/CGrassin/vhdl_cpu.
Auteur : Charles Grassin
What is on your mind?
Sorry, comments are temporarily disabled.
No comment yet!