Introduction
Credential security is often viewed from the software perspective: encryption algorithms, hashing robustness to brute-forcing, etc. However, the hardware may give significant cues. It can be an alternate, simpler, attack medium for eavesdroppers.
At a distance, there are two main passive ways to pick up some information from the hardware without a direct line of sight: electromagnetic waves and sound. EM is split into voluntary emissions from wireless keyboards for instance (but those are often encrypted) and involuntary EMI. For audio, because keyboards are mechanical devices, each key may create a slightly different sound due to various manufacturing considerations. The fact that keys make a somewhat unique sound is a vulnerability. Although it is not easily picked up by our ear, it can be exploited by an algorithm.
This diagram shows the attack medium explored in this article:

In a large recording, there are several indications that makes a password input easy to extract: entered quickly, often followed by ENTER or a click. We then need to process the audio data to get a character sequence.
In this article, I researched algorithms to recover passwords or any other kinds of entry from keyboards using a microphone, some digital signal processing and machine learning techniques.
Video
This video shows the project:
Implementation
Because of time budget and computational power constraints, I chose to tackle, as a proof-of-concept, a subset of the previously described problem. I only considered 7 alphanumeric keys out of the 48 or so individual keys that may be used in password entries. This greatly reduces the search space which will make my probability of success too optimistic, but it does not affect the underlying demonstration as long as statistical significance is reached.
Setup
I recorded sound using a Fifine K669B USB microphone sampling at 44100Hz, a Dell SK-8115 keyboard and the open-source software Audacity. This is my setup:

The advantage of using a desktop keyboard with deep keys like this one is that it emits quite a lot of noise, making the signal-to-noise ratio (SNR) very good compared to a chicklet keyboard from a laptop. Also, this particular model is very popular in offices.
In practice, in a less ideal situation, an highly directional microphone should be used to capture the signal from a distance while minimizing the amount of background noise. A parabolic microphone can have a very long range, that is proportional to the size of the reflector.
These are the normalized waveform of two different key presses, side by side, with their spectrum under (the module of the discrete Fourier transform):
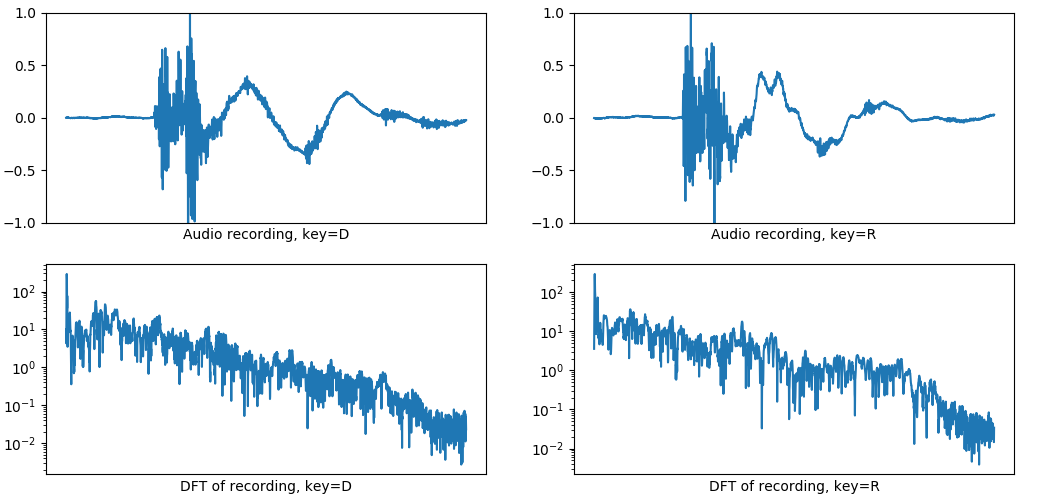
All of the key-specific information is contained within the first 20-50ms after activation. Although the difference is quite noticeable to the ear, it does not really show on these graphs because of the noise nature.
I tried to directly identify the key presses using a digital signal processing (DSP) approach, by comparing an unknown recording to a labeled set:
- Comparing the cross-correlation/convolution between the waveform,
- Comparing the Euclidean distance or the average area between the Discrete Fourier Transform of each known and unknown waveform, in the complex domain.
These computations did not give a satisfactory statistical significance, even in ideal recording conditions. The main issue is that a single key can make several sounds depending on how it is pressed. Another limitation of the pure DSP approach is the volume of data and the need to process, add filters, gate te input, etc.
Hence, this problem is an obvious opportunity for machine learning with an artificial neural network for processing and decision making.
Using machine learning
This problem looks like a classic classification exercise with:
- Input: a large vector containing thousands of audio samples,
- Output: classes for the individual keys with a probability for each.
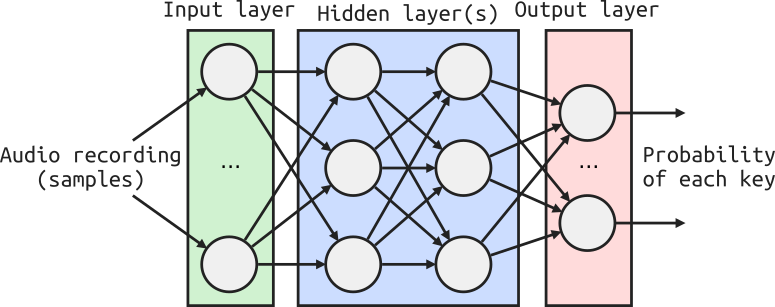
This can be solved with a fairly simple multi-layer perceptron (MLP) network with non-linear activation functions and few hidden layers. I also tried using a 1D convolutional neural network (CNN) with no noticeable improvement.
This is the summary() of my final model:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 3500) 3328500
_________________________________________________________________
dense_2 (Dense) (None, 3500) 12253500
_________________________________________________________________
dense_3 (Dense) (None, 70) 245070
_________________________________________________________________
dense_4 (Dense) (None, 35) 2485
_________________________________________________________________
dense_5 (Dense) (None, 35) 1260
_________________________________________________________________
dense_6 (Dense) (None, 35) 1260
_________________________________________________________________
dense_7 (Dense) (None, 7) 252
=================================================================I used Python3 with the Keras framework and a Tensorflow backend. Training was performed on a dataset of about 5000 labeled recordings of keypresses. 10% of this set is used for validation.
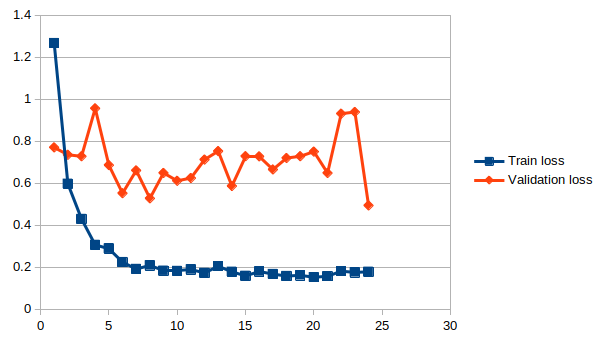 Graph of the training process: loss vs epochs
Graph of the training process: loss vs epochs
After 25 epochs with Nadam optimizer using a sparse categorical crossentropy loss function, we can test its predictions on some other recordings with unknown inputs.
Results
For instance, as a first test, this is a recording of typing the word "PASSWORD":
From this recording, my model makes the following prediction:
D R O S W P A Prediction
00% 01% 00% 00% 00% 00% 99% -> A
00% 00% 00% 00% 00% 00% 99% -> A
00% 00% 00% 100% 00% 00% 00% -> S
00% 00% 00% 100% 00% 00% 00% -> S
00% 00% 00% 00% 100% 00% 00% -> W
18% 17% 25% 03% 12% 06% 18% -> O
00% 100% 00% 00% 00% 00% 00% -> R
100% 00% 00% 00% 00% 00% 00% -> DTo test the robustness of the predictions, I tried adding some background noise, music and other alterations that were not present in the training set. For instance, in this case, I mixed some background crowd noise using Audacity:
This is the result:
D R O S W P A Prediction
01% 02% 00% 00% 00% 00% 97% -> A (or R, D)
06% 00% 00% 00% 91% 00% 02% -> W (or D, A)
00% 00% 00% 100% 00% 00% 00% -> S
00% 00% 00% 100% 00% 00% 00% -> S
00% 00% 00% 02% 97% 00% 00% -> W (or S)
25% 20% 16% 05% 14% 05% 15% -> D (or R, O, A...)
100% 00% 00% 00% 00% 00% 00% -> D
100% 00% 00% 00% 00% 00% 00% -> DAs expected, the accuracy dropped, but the search space still got a lot smaller. This technique should be expended by either manually reviewing the data or by processing the output using the Levenshtein distance, comparing with common passwords lists and dictionaries with standard characters permutations. The higher the accuracy, the better chance of success, but a 100% accuracy is not at all a requirement to get reliable output.
Because I had access to a second Dell SK-8115 keyboard, I checked how transferable the learning performed on one keyboard is to another keboard. The ANN never heard this device before, but the microphone is identical. This is the recording:
The similarity with the previous device is already noticable to the ear. The neural network's output is:
D R O S W P A Prediction
00% 00% 00% 00% 00% 100% 00% -> P
06% 01% 01% 80% 03% 00% 08% -> S
00% 00% 00% 100% 00% 00% 00% -> S
98% 01% 00% 00% 00% 00% 00% -> D
00% 00% 01% 08% 84% 01% 06% -> W
00% 00% 100% 00% 00% 00% 00% -> O
08% 01% 02% 06% 05% 08% 71% -> A
100% 00% 00% 00% 00% 00% 00% -> DThis shows that the learning process using this method may be transfered to another keyboard of the same model. A bigger sample would be required to make a conclusion. Note that both keyboards were ordered at the same time, and may come from the same manufacturing batch.
Discussion
As demonstrated, this technique does work in this ideal setup: it is able to extract the key presses from an audio recording. It is very powerful because it reduces the entropy of the search a lot: we know the length of the input and the key presses up to some accuracy. Of course, it could be used on recordings on entire texts but I chose to tackle the password input.
We could even compensate a lower accuracy with some social engineering techniques, or dictionaries as detailed earlier.
My Python code with some instructions is on GitHub: https://github.com/CGrassin/keyboard_audio_hack
Limitations
My implementation is a proof-of-concept. It is not directly usable as a practical attack because it requires a labeled train set. However, this is not an obstacle, only a second task to tackle. Indeed, this information can be obtained by recording a lot of typing and using sound similarity, statistics and dictionary to recover the keys corresponding to each sound.
In practice, the effectiveness will be greatly limited by the SNR of the recording. This might be circumventable with more training samples in said environment and/or better data pre-processing (filtering).
Mitigation
Although my implementation is a simple proof-of-concept, it proves that this attack medium is viable, and can be a threat. In fact, it is vile because the length and complexity of the password doesn't have a very negative outcome on the probability of success.
Using a somewhat silent keyboard will reduce the SNR, especially in a noisy environment. This will make the prediction less reliable, but may be circumvented by the attacker by using more data or better recording hardware.
The use of an on-screen input method such as banking PINs render this attack useless but usually makes the user more vulnerable to visual eavesdropping.
Using a locally stored password manager is another, better solution, as getting the master password would not give any usable passwords, unless access to the computer is gained.
Sources and previous work
- D. Asonov and R. Agrawal (2004). Keyboard acoustic emanations, from https://ieeexplore.ieee.org/abstract/document/1301311
- Alberto Compagno, Mauro Conti, Daniele Lain and Gene Tsudik (2017). Don't Skype & Type! Acoustic Eavesdropping in Voice-Over-IP, from https://arxiv.org/abs/1609.09359
- Georgi Gerganov (2018). Keytap: acoustic keyboard eavesdropping, from https://ggerganov.github.io/jekyll/update/2018/11/24/keytap.html
Author: Charles Grassin
What is on your mind?
Sorry, comments are temporarily disabled.
Related articles
No related projects were found.
No comment yet!